

Table of Contents
The world’s most popular code language for data analysis just got a little simpler. We have demonstrated simple and effective ways to run SQL queries in Python and R, especially for data analysis and database management.
What is SQL?
Structured Query Language (SQL) is the most commonly used language to perform various data analysis tasks. It is also used to maintain relational databases, e.g. adding tables, deleting values, and optimizing the database.
A simple relational database consists of several interconnected tables, and each table consists of rows and columns. The average technology company generates millions of data points every day. A powerful and efficient storage solution is needed to be able to use data to improve existing systems or launch new products. Relational databases such as MySQL, PostgreSQL, and SQLite solve these problems by providing powerful, secure, and high-performance database management capabilities.
Basic SQL functions
- Create a new table in a database
- Run a query on a database
- Retrieve data from a database
- Insert records into a database
- Update a table records in database
- Delete records from database
- Optimize any database
SQL is a high-demand skill that will help you get any job in the tech industry. Companies like Meta, Google, and Netflix are always looking for data experts who can extract insights from SQL databases and come up with creative solutions. You can learn the basics of SQL by following the Introduction to SQL tutorial on DataCamp.
Why use SQL with Python and R?
1: Which of the following data types is immutable in Python?
SQL can help us discover business performance, understand customer behavior, and track marketing campaign success metrics. Most data analysts can perform the majority of business intelligence tasks by running SQL queries, so why do we need tools like PoweBI, Python, and R? Using SQL queries, you can know what happened in the past but you cannot predict future predictions. These tools help us better understand current performance and potential growth.
Python and R are flexible languages that enable professionals to run advanced statistical analysis, build machine learning models, build data APIs, and ultimately help businesses think beyond KPIs. In this tutorial, we will learn how to connect to a SQL database, populate the database, and run SQL queries using Python and R.
Note: If you are new to SQL, follow the SQL Skills Path to understand the fundamentals of writing SQL queries.
Unlock Your Coding Potential with Our Python Programming Course – Enroll Today
🚀 Start Coding Today! Enroll Now with Easy EMI Options. 💳✨
Gain expertise in Django and open doors to lucrative opportunities in web development.
Start Learning With EMI Payment OptionsPython Tutorial
Python Tutorial will cover the basics of connecting to various databases (MySQL and SQLite), creating tables, adding records, running queries, and learning functions Pandas read_sql.
Configuration
We can connect to the database using SQLAlchemy, but in this tutorial we will use Python’s built-in SQLite3 package to run queries against the database. SQLAlchemy supports all types of databases by providing a unified API. If you want to learn more about SQLAlchemy and how it works with other databases, check out the course Introduction to Databases in Python.
MySQL is the world’s most popular database engine and is widely used by companies such as Youtube, Paypal, LinkedIn and GitHub.Here we will learn how to connect the database. The remaining steps to use MySQL are similar to the SQLite3 package.
First install the mysql package using ‘!pip install mysql’, then create the local database engine by providing your username, password and database name.
import mysql.connector as sql
conn = sql.connect(
host=”localhost”,
user=”abid”,
password=”12345″,
database=”datacamp_python”
)
- This code imports the mysql.connector module and assigns it the alias sql.
- It then establishes a connection to a MySQL database using the connect() method of the sql module.
- The connect() method takes several parameters, including the host (the server where the database is located), user (the username to connect to the database), password (the password for the user), and database (the name of the database to connect to).
- In this case, the code connects to a database named datacamp_python on the local machine using the username abid and password 12345.
Similarly, we can create or load an SQLite database using the sqlite3.connect function. SQLite is a library that implements a serverless, standalone, zero-configuration database engine. It is compatible with DataCamp Workspace, so we will use it in our project to avoid local server errors.
import sqlite3
import pandas as pd
conn= sqlite3.connect(“datacamp_python.db”)
- This code imports the sqlite3 and pandas modules into Python.
- It then creates a connection to the SQLite database named “datacamp_python.db” using the connect() method of the sqlite3 module.
- The connection object is stored in the conn variable.
- This connection object can be used to execute SQL queries and interact with the database.
- The pandas module can also be used to read data from the database into a DataFrame for further analysis.
Creating a Database
In this section, we will learn how to load the COVID-19 Impact on Airport Traffic dataset, licensed under CC BY-NC-SA 4.0, into our SQLite database. We will also learn how to create a table from scratch.
The airport traffic dataset includes the percentage of traffic volume for the reporting period from February 1, 2020 to March 15, 2020. We will load the CSV file using the Pandas read_csv function, then use the to_sql function to pass the data frame into a SQLite table. The to_sql function requires a table name (String) and connects to the SQLite engine.
data = pd.read_csv(“data/covid_impact_on_airport_traffic.csv”)
data.to_sql(
‘airport’, # Name of the sql table
conn, # sqlite.Connection or sqlalchemy.engine.Engine
if_exists=’replace’
)
Now we will test whether we were successful or not by running a quick SQL query. Before running the query, we need to create a cursor that helps us run the query as shown in the code block below.
Unlock Your Coding Potential with Our Python Programming Course – Enroll Today
You can have multiple cursors on the same database in one connection. In our case, the SQL query returns three columns and five rows from the Airports table. To display the first row, we will use cursor.fetchone().
cursor = conn.cursor()
cursor.execute(“””SELECT Date, AirportName, PercentOfBaseline
FROM airport
LIMIT 5″””)
cursor.fetchone()
>>> (‘2020-04-03’, ‘Kingsford Smith’, 64)
To show the remaining of the records, we will use cursor.fetchall(). The airport dataset is loaded into the database with a few lines of code successfully.
cursor.fetchall()
[(‘2020-04-13’, ‘Kingsford Smith’, 29),(‘2020-07-10’, ‘Kingsford Smith’, 54),
(‘2020-09-02’, ‘Kingsford Smith’, 18),
(‘2020-10-31’, ‘Kingsford Smith’, 22)]
Now learn how to create a table from scratch and populate it by adding sample values. We will create a student information table with id (integer, primary key, auto-increment), name (text), and subject (text).
Note: The SQLite syntax is a bit different. You should review the SQLite cheat sheet to understand the SQL queries covered in this tutorial.
cursor.execute(“””
CREATE TABLE studentinfo
(
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
subject TEXT
)
“””)
Let’s check how many tables we’ve added to the database by running a simple SQLite query.
cursor.execute(“””
SELECT name
FROM sqlite_master
WHERE type=’table’
“””)
cursor.fetchall()
>>> [(‘airport’,), (‘studentinfo’,)]
Running a query
In this section we will add values to the student information table and run simple SQL queries. Using INSERT INTO we can add a row to the student information table.
To insert values, we need to provide the query and value arguments to the execute function. This function responds to “? ” items we provide.
query = “””
INSERT INTO studentinfo
(name, subject)
VALUES (?, ?)
“””
value = (“Marry”, “Math”)
cursor.execute(query,value)
Repeat the query on more records.
query = “””
INSERT INTO studentinfo
(name, subject)
VALUES (?, ?)
“””
values = [(“Abid”, “Stat”),
(“Carry”, “Math”),
(“Ali”,”Data Science”),
(“Nisha”,”Data Science”),
(“Matthew”,”Math”),
(“Henry”,”Data Science”)]
cursor.executemany(query,values)
It’s time to check the file. To do this, we will run a simple SQL query that will return rows whose subject is Data Science.
cursor.execute(“””
SELECT *
FROM studentinfo
WHERE subject LIKE ‘Data Science’
“””)
cursor.fetchall()
>>> [(4, ‘Ali’, ‘Data Science’),
(5, ‘Nisha’, ‘Data Science’),
(7, ‘Henry’, ‘Data Science’)]
The DISTINCT subject command is used to display unique values contained in subject columns. In our case, this is mathematics, statistics and data science.
cursor.execute(“SELECT DISTINCT subject from studentinfo”)
cursor.fetchall()
>> [(‘Math’,), (‘Stat’,), (‘Data Science’,)]
To save all the changes, we will use the commit() function. If not authenticated, data will be lost after restarting the device.
conn.commit()
🚀 Start Coding Today! Enroll Now with Easy EMI Options. 💳✨
Gain expertise in Django and open doors to lucrative opportunities in web development.
Start Learning With EMI Payment OptionsSQL with Pandas
In this section, we will learn how to extract data from an SQLite database and convert it to a Pandas data frame using a single line of code. read_sql provides more than just executing SQL queries. We can use it to define index columns, parse date and time, add values, and filter column names. Learn more about importing data with Python by taking the short DataCamp course.
read_sql requires two arguments: an SQL query and a connection to the SQLite engine. The output contains the first five rows of the airports table where PercentOfBaseline is greater than 20.
data_sql_1 = pd.read_sql(“””
SELECT Date,City,PercentOfBaseline
FROM airport
WHERE PercentOfBaseline > 20
ORDER BY Date DESC
“””,
conn)
print(data_sql_1.head())
Date City PercentOfBaseline
0 2020-12-02 Sydney 27
1 2020-12-02 Santiago 48
2 2020-12-02 Calgary 99
3 2020-12-02 Leduc County 100
4 2020-12-02 Richmond 86
Unlock Your Coding Potential with Our Python Programming Course – Enroll Today
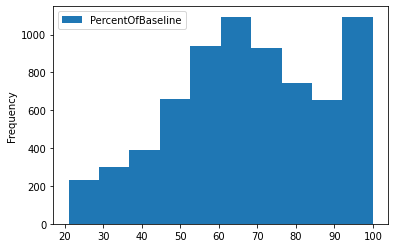
Performing data analytics on relational databases has become easier with the Pandas integration. We can also use this data to predict values and perform complex statistical analyses. The plot function allows you to visualize a histogram of the PercentOfBaseline column.
data_sql_1.plot(y=”PercentOfBaseline”,kind=”hist”);
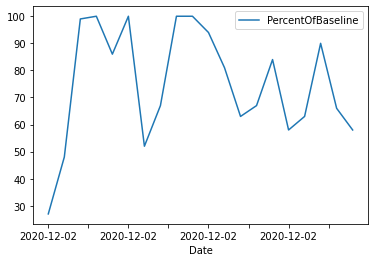
Similarly, we can limit the values to the first 20 values and display a time series line chart.
data_sql_2 = pd.read_sql(“””
SELECT Date,City,PercentOfBaseline
FROM airport
WHERE PercentOfBaseline > 20
ORDER BY Date DESC
LIMIT 20
“””,
conn)
data_sql_2.plot(x=”Date”,y=”PercentOfBaseline”,kind=”line”);
Finally we will close the connection to free up resources. Most packages do this automatically, but it’s best to close the connection after the changes are complete.
conn.close()
R Tutorial
We will copy all the tasks from the Python tutorial using R. The tutorial covers creating connections, writing tables, adding rows, running queries, and analyzing data using dplyr.
Configuration
The DBI package is used to connect to the most popular databases such as MariaDB, Postgres, Duckdb and SQLite. For example, install the RMySQL package and create a database by providing a username, password, database name, and server address.
install.packages(“RMySQL”)
library(RMySQL)
conn = dbConnect(
MySQL(),
user = ‘abid’,
password = ‘1234’,
dbname = ‘datacamp_R’,
host = ‘localhost’
)
In this tutorial, we will create an SQLite database by providing an SQLite name and function.
library(RSQLite)
library(DBI)
library(tidyverse)
conn = dbConnect(SQLite(), dbname = ‘datacamp_R.db’)
Unlock Your Coding Potential with Our Python Programming Course – Enroll Today
Creating Database
By importing the Tidyverse library we will have access to the dplyr, ggplot and default datasets.
The dbWriteTable function takes the data.frame and adds it to the SQL table. It takes three arguments: the connection to SQLite, the table name, and the data frame. With dbReadTable we can view the entire table. To display the first 6 lines we use head.
dbWriteTable(conn, “cars”, mtcars)
head(dbReadTable(conn, “cars”))
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
6 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
dbExecute allows us to execute any SQLite query, so we will use it to create a table called idcard.
To display table names in the database, we will use dbListTables.
dbExecute(conn, ‘CREATE TABLE idcard (id int, name text)’)
dbListTables(conn)
>>> ‘cars”idcard’
Let’s add a row to the idcard table and use dbGetQuery to display the results.
Note: dbGetQuery executes the query and returns records while dbExecute executes the SQL query but returns no records.
dbExecute(conn, “INSERT INTO idcard (id,name)\
VALUES(1,’love’)”)
dbGetQuery(conn,”SELECT * FROM idcard”)
id name
1 love
Now we will add two more rows and display the results using dbReadTable.
dbExecute(conn,”INSERT INTO idcard (id,name)\
VALUES(2,’Kill’),(3,’Game’)
“)
dbReadTable(conn,’idcard’)
id name
1 love
2 Kill
3 Game
dbCreateTable allows us to create tables easily. This requires three arguments; connection, table name, and character vector or data.frame. Character vector includes name (column name) and value (type). In our case, we will provide a default population data.frame to create the initial structure.
dbCreateTable(conn,’population’,population)
dbReadTable(conn,’population’)
country year population
Next, we will use dbAppendTable to add values to the population table.
dbAppendTable(conn,’population’,head(population))
dbReadTable(conn,’population’)
country year population
Afghanistan 1995 17586073
Afghanistan 1996 18415307
Afghanistan 1997 19021226
Afghanistan 1998 19496836
Afghanistan 1999 19987071
Afghanistan 2000 20595360
Running Queries
We will use dbGetQuery to perform all of our data analytics tasks. Let’s try to run a simple query and then learn more about other functions.
dbGetQuery(conn,”SELECT * FROM idcard”)
id name
1 love
2 Kill
3 Game
You can also run a complex SQL query to filter and display limited rows and columns.
dbGetQuery(conn, “SELECT mpg,hp,gear\
FROM cars\
WHERE hp > 50\
LIMIT 5”)
mpg hp gear
21.0 110 4
21.0 110 4
22.8 93 4
21.4 110 3
18.7 175 3
To remove a table, use dbRemoveTable. As we can see now we have successfully removed the ID card table.
dbRemoveTable(conn,’idcard’)
dbListTables(conn)
>>> ‘cars”population’
To understand tables better, we will use dbListFields to display column names in a particular table.
dbListFields(conn, “cars”)
>>> ‘mpg”cyl”disp”hp”drat”wt”qsec”vs”am”gear”carb’
SQL with dplyr
In this section, we will use dplyr to read the table and then run queries using filter, select, and collect. If you don’t want to learn SQL syntax and want to do all the tasks in pure R, then this method is for you. We extract the cars table, filter by speed and mpg, then select three columns as shown below.
cars_results <-
tbl(conn, “cars”) %>%
filter(gear %in% c(4, 3),
mpg >= 14,
mpg <= 21) %>%
select(mpg, hp, gear) %>%
collect()
cars_results
mpg hp gear
21.0 110 4
21.0 110 4
18.7 175 3
18.1 105 3
14.3 245 3
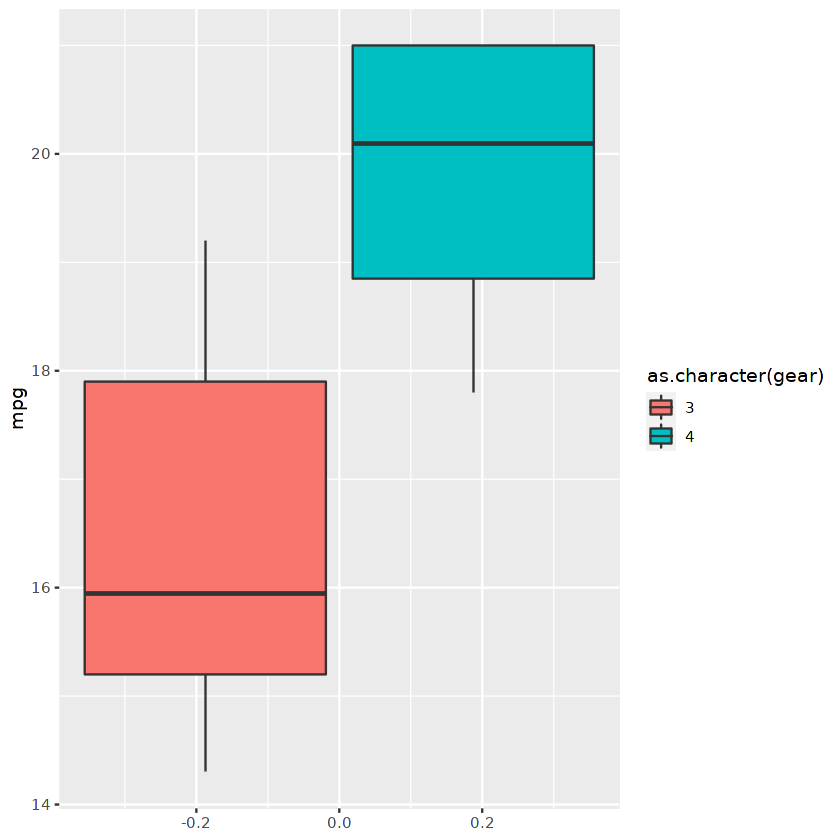
We can use a filtered data frame to display a box and whisker plot using ggplot.
ggplot(cars_results,aes(fill=as.character(gear), y=mpg)) +
geom_boxplot()
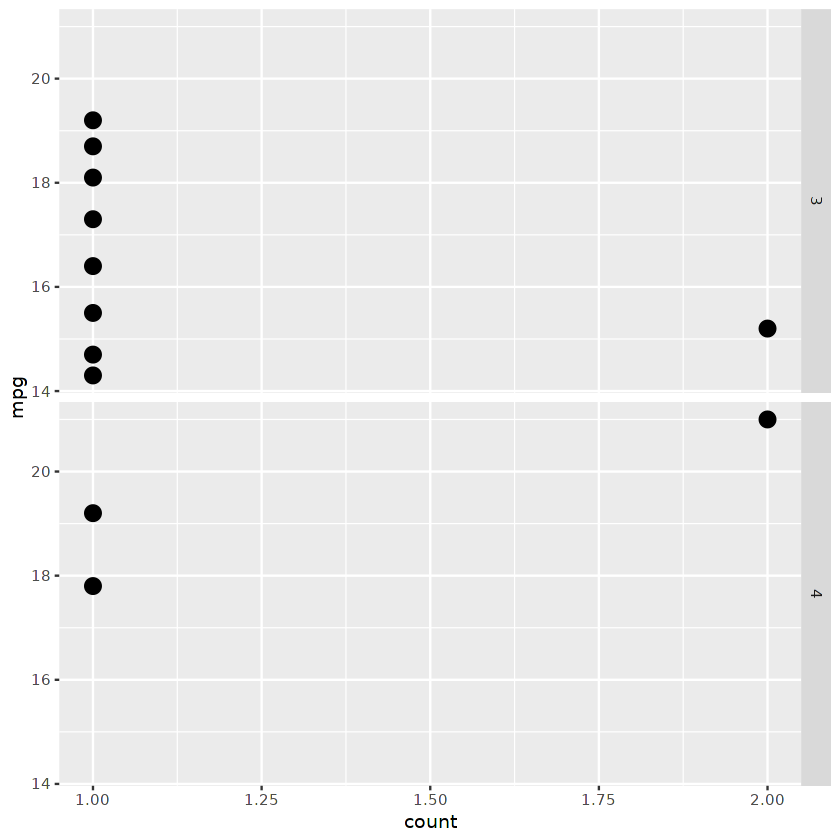
Or we can display a facet point plot divided by the number of gears.
ggplot(cars_results,
aes(mpg, ..count.. ) ) +
geom_point(stat = “count”, size = 4) +
coord_flip()+
facet_grid( as.character(gear) ~ . )
Unlock Your Coding Potential with Our Python Programming Course – Enroll Today
Conclusion
In this tutorial, we learned the importance of running SQL queries with Python and R, creating databases, adding tables, and performing data analysis using SQL queries. We also learned how Pandas and dplyr help us run queries with just one line of code.
SQL is an essential skill for any technology-related job. If you are starting your career as a Data Analyst, we recommend completing the Data Analyst with SQL Server career path within two months. This career path will teach you all about SQL queries, servers, and resource management.











{kind=link}