

Table of Contents
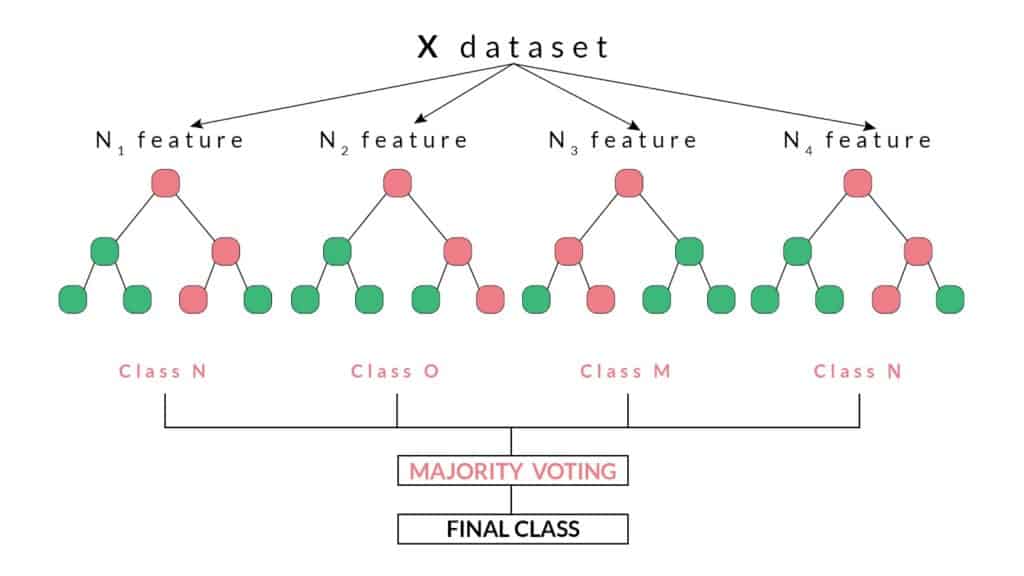
Every decision tree has high variance, but when we combine all of them together in parallel then the resultant variance is low as each decision tree gets perfectly trained on that particular sample data, and hence the output doesn’t depend on one decision tree but on multiple decision trees. In the case of a classification problem, the final output is taken by using the majority voting classifier. In the case of a regression problem, the final output is the mean of all the outputs. This part is called Aggregation.
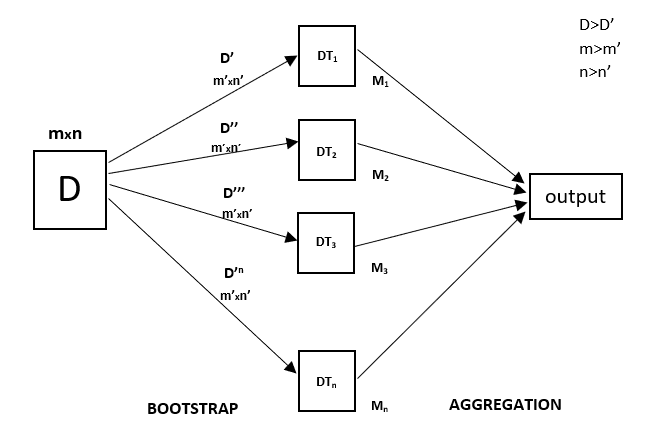
Random Forest is an ensemble technique capable of performing both regression and classification tasks with the use of multiple decision trees and a technique called Bootstrap and Aggregation, commonly known as bagging. The basic idea behind this is to combine multiple decision trees in determining the final output rather than relying on individual decision trees.
Random Forest has multiple decision trees as base learning models. We randomly perform row sampling and feature sampling from the dataset forming sample datasets for every model. This part is called Bootstrap.
“Ready to take your python skills to the next level? Sign up for a free demo today!”
We need to approach the Random Forest regression technique like any other machine learning technique
- Design a specific question or data and get the source to determine the required data.
- Make sure the data is in an accessible format else convert it to the required format.
- Specify all noticeable anomalies and missing data points that may be required to achieve the required data.
- Create a machine learning model
- Set the baseline model that you want to achieve
- Train the data machine learning model.

be a python programmer ! learn from the best !
Definitions:
Decision Trees are used for both regression and classification problems. They visually flow like trees, hence the name, and in the regression case, they start with the root of the tree and follow splits based on variable outcomes until a leaf node is reached and the result is given. An example of a decision tree is below:

Here we see a basic decision tree diagram which starts with the Var_1 and splits based off of specific criteria. When ‘yes’, the decision tree follows the represented path, when ‘no’, the decision tree goes down the other path. This process repeats until the decision tree reaches the leaf node and the resulting outcome is decided. For the example above, the values of a, b, c, or d could be representative of any numeric or categorical value.
To summarize, we started with some theoretical information about Ensemble Learning, ensemble types, Bagging and Random Forest algorithms and went through a step-by-step guide on how to use Random Forest in Python for the Regression task. Also, we compared Random Forest with some other ML Regression algorithms. Lastly, we talked about some tips you may find useful when working with Random Forest.

Related Articles
| Our Other Courses | ||
| MEP Course | Quantity Surveying Course | Montessori Teachers Training Course |
| Performance Marketing Course | Practical Accounting Course | Yoga Teachers Training Course |









{kind=link}