

Table of Contents
Introduction
Data science is a combination of mathematics, business knowledge, tools, algorithms, and machine learning techniques that aid in the discovery of hidden insights or patterns in raw data that can be used to make critical business decisions. In data science, both structured and unstructured data are dealt with. Predictive analytic is also used in the algorithms. Thus, data science is concerned with the present and future. That is, identifying trends based on historical data that can be used to make current decisions, as well as identifying patterns that can be modeled and used to make forecasts of how things might look in the future. This article on Top 100 Data Science Interview Questions and Answers 2025 will provide you with information on basic data science interview questions and other information.
The art of discovering insights and trends in data has been around since the beginning of time. The ancient Egyptians used census data to increase tax collection efficiency, and they accurately predicted Nile river flooding every year. Since then, people who work in data science have carved out a distinct and distinct field for their work. This is the field of data science. Let us take a look at common data science interview questions below.
Ready to take your data science skills to the next level? Sign up for a free demo today!
Free Tutorials To Learn
| SQL Tutorial for Beginners PDF – Learn SQL Basics | |
| HTML Exercises to Practice | HTML Tutorial | |
| DSA Practice Series | DSA Tutorials | |
| Java Programming Notes PDF |
Top 100 Data Science Interview Questions and Answers 2025
1: Which of the following algorithms is most suitable for classification tasks?
1. What is Data Science?
In a nutshell, data science is an interdisciplinary field of study that uses data for various research and reporting purposes in order to derive insights and meaning from that data. Data science necessitates a diverse set of skills, including statistics, business acumen, computer science, and others.
2. What is Selection Bias?
A type of error that occurs when the researcher decides who will be studied is selection bias. It is usually associated with research in which the participants are not chosen at random. The selection effect is another name for it. It is a distortion of statistical analysis caused by the method of sample collection. If the selection bias is not considered, some of the study’s conclusions may be incorrect.
3. What’s the distinction between point estimates and confidence intervals?
As an estimate of a population parameter, point estimation provides us with a specific value. Point Estimators for population parameters are derived using the Method of Moments and Maximum Likelihood estimator methods.
A confidence interval provides us with a range of values that are likely to contain the population parameter. The confidence interval is generally preferred because it tells us how likely it is that this interval will contain the population parameter. This likelihood or probability is known as the Confidence Level or Confidence Coefficient, and it is represented by the number 1 — alpha, where alpha is the level of significance.
4. What Is the Law of Large Numbers?
It is a theorem that describes the outcome of repeating the same experiment many times. This theorem serves as the foundation for frequency-style reasoning. It states that the sample means, variance, and standard deviation converge to what they are attempting to estimate.
5. What is Survivorship Bias?
It is the logical error of focusing on aspects that aid in the survival of a process while casually ignoring those that did not work due to their lack of prominence. This can lead to incorrect conclusions in a variety of ways.
6. What is TF/IDF vectorization?
The term frequency–inverse document refers to a document that has a frequency that is The term frequency, abbreviated as TF–IDF, refers to a numerical statistic that indicates the importance of a word in a collection or corpus to a document.
The TF–IDF value rises proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus, which explains why some words appear more frequently than others.
7. What is Systematic Sampling?
Systematic sampling is a statistical technique that involves selecting elements from an ordered sampling frame. In systematic sampling, the list is progressed in a circular fashion, so when you reach the end of the list, it is restarted from the beginning. The best example of systematic sampling is the equal probability method.
8. Explain Cross Validation.
Cross-validation is a model validation technique that is used to determine how statistical analysis results will generalize to a different data set. Typically used in situations where the goal is to forecast and one wants to estimate how accurately a model will perform in practice. The goal of cross-validation is to define a data set to test the model in the training phase (i.e. validation data set) in order to limit over fitting and gain insight into how the model will generalize to an independent data set.
9. What is pruning in Decision Tree?
Pruning is a technique used in machine learning and search algorithms to shrink decision trees by removing branches with little power to classify instances. So, when we remove sub-nodes from a decision node, we call this process pruning, which is the inverse of splitting.
10. What is the distinction between Regression and Classification Machine Learning techniques?
Supervised machine learning algorithms include both regression and classification machine learning techniques. We must train the model using a labeled data set in the Supervised machine learning algorithm. During training, we must explicitly provide the correct labels, and the algorithm attempts to learn the pattern from input to output. If our labels are discrete values like A,B, etc., we have a classification problem; if our labels are continuous values like 1.23, 1.333, etc., we have a regression problem.
11. You are given a data set consisting of variables with more than 30 percent missing values. How will you deal with them?
The following are ways to handle missing data values:
If the data set is large, we can just simply remove the rows with missing data values. It is the quickest way; we use the rest of the data to predict the values.
For smaller data sets, we can substitute missing values with the mean or average of the rest of the data using the pandas’ data frame in python. There are different ways to do so, such as df.mean(), df.fillna(mean).
12. What are dimensionality reduction and its benefits?
The Dimensionality reduction refers to the process of converting a data set with vast dimensions into data with fewer dimensions (fields) to convey similar information concisely.
This reduction helps in compressing data and reducing storage space. It also reduces computation time as fewer dimensions lead to less computing. It removes redundant features; for example, there’s no point in storing a value in two different units (meters and inches).
BE A DATA SCIENTIST WITH ENTRI APP! GET A FREE DEMO VIDEO!
13. What are recommender systems?
A recommender system predicts what a user would rate a specific product based on their preferences. It can be split into two different areas:
Collaborative Filtering
As an example, Last.fm recommends tracks that other users with similar interests play often. This is also commonly seen on Amazon after making a purchase; customers may notice the following message accompanied by product recommendations: “Users who bought this also bought…”
Content-based Filtering
As an example: Pandora uses the properties of a song to recommend music with similar properties. Here, we look at content, instead of looking at who else is listening to music.
14. What is a Confusion Matrix?
The Confusion Matrix is the summary of prediction results of a particular problem. It is a table that is used to describe the performance of the model. The Confusion Matrix is an n*n matrix that evaluates the performance of the classification model.
15. What is the difference between true-positive rate and false-positive rate?
TRUE-POSITIVE RATE: The true-positive rate gives the proportion of correct predictions of the positive class. It is also used to measure the percentage of actual positives that are accurately verified.
FALSE-POSITIVE RATE: The false-positive rate gives the proportion of incorrect predictions of the positive class. A false positive determines something is true when that is initially false.
16. How is Data Science different from traditional application programming?
The primary and vital difference between Data Science and traditional application programming is that in traditional programming, one has to create rules to translate the input to output. In Data Science, the rules are automatically produced from the data.
17. Why is Python used for Data Cleaning in DS?
Data Scientists and technical analysts must convert a huge amount of data into effective ones. Data Cleaning includes removing malwared records, outliners, inconsistent values, redundant formatting etc. Matplotlib, Pandas etc are the most used Python Data Cleaners.
18. What is pruning in a decision tree algorithm?
In Data Science and Machine Learning, Pruning is a technique which is related to decision trees. Pruning simplifies the decision tree by reducing the rules. Pruning helps to avoid complexity and improves accuracy. Reduced error Pruning, cost complexity pruning etc. are the different types of Pruning.
19. What is k-fold cross-validation?
The k-fold cross validation is a procedure used to estimate the model’s skill in new data. In k-fold cross validation, every observation from the original dataset may appear in the training and testing set. K-fold cross-validation estimates the accuracy but does not help you to improve the accuracy.
20. What is the difference between the long format data and wide format data?
LONG FORMAT DATA: It contains values that repeat in the first column. In this format, each row is a one-time point per subject.
WIDE FORMAT DATA: In the Wide Format Data, the data’s repeated responses will be in a single row, and each response can be recorded in separate columns.
Looking for a Data Science Career? Explore Here!
21. What is an RNN (recurrent neural network)?
RNN is an algorithm that uses sequential data. RNN is used in language translation, voice recognition, image capturing etc. There are different types of RNN networks such as one-to-one, one-to-many, many-to-one and many-to-many. RNN is used in Google’s Voice search and Apple’s Siri.
22. What is entropy in a decision tree algorithm?
Entropy is the measure of randomness or disorder in the group of observations. It also determines how a decision tree switches to split data. Entropy is also used to check the homogeneity of the given data. If the entropy is zero, then the sample of data is entirely homogeneous, and if the entropy is one, then it indicates that the sample is equally divided.
23. What are recommender systems?
Recommender systems are a subclass of information filtering systems that are meant to predict the preferences or ratings that a user would give to a product.
24. What are the confounding variables?
These are extraneous variables in a statistical model that correlates directly or inversely with both the dependent and the independent variable. The estimate fails to account for the confounding factor.
25. What are the popular libraries used in Data Science?
The popular libraries used in Data Science are
- Tensor Flow
- Pandas
- NumPy
- SciPy
- Scrapy
- Librosa
- MatPlotLib
26. What are eigenvalue and eigenvector?
Eigenvalues are the directions along which a particular linear transformation acts by flipping, compressing, or stretching.
Eigenvectors are for understanding linear transformations. In data analysis, we usually calculate the eigenvectors for a correlation or covariance matrix.
27. What is selection bias?
Selection bias is a problematic situation in which error is introduced due to a non-random population sample.
28. What is the goal of A/B Testing?
This is statistical hypothesis testing for randomized experiments with two variables, A and B. The objective of A/B testing is to detect any changes to a web page to maximize or increase the outcome of a strategy.
29. What is root cause analysis?
Root cause analysis was initially developed to analyze industrial accidents but is now widely used in other areas. It is a problem-solving technique used for isolating the root causes of faults or problems. A factor is called a root cause if its deduction from the problem-fault-sequence averts the final undesirable event from recurring.
30. What is collaborative filtering?
Most recommender systems use this filtering process to find patterns and information by collaborating perspectives, numerous data sources, and several agents.
31. What are the types of biases that can occur during sampling?
- Selection bias
- Undercoverage bias
- Survivorship bias
32. What are the drawbacks of the linear model?
- The assumption of linearity of the errors
- It can’t be used for count outcomes or binary outcomes
33. What is collaborative filtering?
Most recommender systems use this filtering process to find patterns and information by collaborating perspectives, numerous data sources, and several agents.
34. What is star schema?
It is a traditional database schema with a central table. Satellite tables map IDs to physical names or descriptions and can be connected to the central fact table using the ID fields; these tables are known as lookup tables and are principally useful in real-time applications, as they save a lot of memory. Sometimes, star schemas involve several layers of summarization to recover information faster.
HEAD START YOUR CAREER WITH DATA SCIENCE ONLINE CERTIFICATION !
35. What does NLP stand for?
NLP is short for Natural Language Processing. It deals with the study of how computers learn a massive amount of textual data through programming. A few popular examples of NLP are Stemming, Sentimental Analysis, Tokenization, removal of stop words, etc.
36. Out of Python and R, which is your preference for performing text analysis?
Python is likely to be everyone’s choice for text analysis as it has libraries like Natural Language Toolkit (NLTK), Gensim. CoreNLP, SpaCy, TextBlob, etc. are useful for text analysis.
37. What do you know about MLOps tools? Have you ever used them in a machine learning project?
MLOps tools are the tools that are used to produce and monitor the enterprise-grade deployment of machine learning models. Examples of such tools are MLflow, Pachyderm, Kubeflow, etc.
38. What do you understand by feature vectors?
Feature vectors are the set of variables containing values describing each observation’s characteristics in a dataset. These vectors serve as input vectors to a machine learning model.
39. Why does data cleaning play a vital role in the analysis?
It is cumbersome to clean data from multiple sources to transform it into a format that data analysts or scientists can work with. As the number of data sources increases, the time it takes to clean the data increases exponentially due to the number of sources and the volume of data generated in these sources. It might take up to 80% of the time for cleaning data, thus making it a critical part of the analysis task.
40. What are the types of biases that can occur during sampling?
- Selection bias
- Undercoverage bias
- Survivorship bias
Enroll for Data Science and Machine Learning Course Now!
41. What is K-means?
K-means clustering algorithm is an unsupervised machine learning algorithm that classifies a dataset with n observations into k clusters. Each observation is labeled to the cluster with the nearest mean.
42. How will you find the right K for K-means?
To find the optimal value for k, one can use the elbow method or the silhouette method.
43. What do you understand by interpolating and extrapolating the given data?
Interpolating the data means one is estimating the values in between two known values of a variable from the dataset. On the other hand, extrapolating the data means one is estimating the values that lie outside the range of a variable.
44. What is the standard normal distribution?
The standard normal distribution is a special kind of normal distribution in statistics that zero mean and standard deviation equals one. The graph of a standard normal distribution looks like the famous bell curve with zero at its center. As you can see, the distribution is symmetrical around the origin, and asymptomatic.
45. What is multicollinearity, and how can you overcome it?
A single dependent variable depends on several independent variables in a multiple regression model. When these independent variables are deduced to possess high correlations with each other, the model is considered to reflect multicollinearity.
One can overcome multicollinearity in their model by removing a few highly correlated variables from the regression equation.
46. What is dimensionality reduction?
Dimensionality reduction is the process of converting a dataset with a high number of dimensions (fields) to a dataset with a lower number of dimensions. This is done by dropping some fields or columns from the dataset. However, this is not done haphazardly. In this process, the dimensions or fields are dropped only after making sure that the remaining information will still be enough to succinctly describe similar information.
47. What are the popular libraries used in Data Science?
- TensorFlow: Supports parallel computing with impeccable library management backed by Google.
- SciPy: Mainly used for solving differential equations, multidimensional programming, data manipulation, and visualization through graphs and charts.
- Pandas: Used to implement the ETL(Extracting, Transforming, and Loading the datasets) capabilities in business applications.
- Matplotlib: Being free and open-source, it can be used as a replacement for MATLAB, which results in better performance and low memory consumption.
- PyTorch: Best for projects which involve Machine Learning algorithms and Deep Neural Networks.
48. Explain selection bias.
Selection bias is the bias that occurs during the sampling of data. This kind of bias occurs when a sample is not representative of the population, which is going to be analyzed in a statistical study.
49. Do gradient descent methods always converge to the same point?
No, gradient descent methods do not always converge to the same point because they converge to a local minimum or a local optima point in some cases. It depends a lot on the data one is dealing with and the initial values of the learning parameter.
50. How does the use of dropout work as a regulariser for deep neural networks?
Dropout is a regularisation method used for deep neural networks to train different neural networks architectures on a given dataset. When the neural network is trained on a dataset, a few layers of the architecture are randomly dropped out of the network. This method introduces noise in the network by compelling nodes within a layer to probabilistically take on more or less authority for the input values. Thus, dropout makes the neural network model more robust by fixing the units of other layers with the help of prior layers.
Are you aspiring for a booming career in IT? If YES, then dive in |
||
Full Stack Developer Course |
Python Programming Course |
Data Science and Machine Learning Course |
51. What is precision?
When we are implementing algorithms for the classification of data or the retrieval of information, precision helps us get a portion of positive class values that are positively predicted. Basically, it measures the accuracy of correct positive predictions. Below is the formula to calculate precision:

52. What is a recall?
It is the set of all positive predictions out of the total number of positive instances. Recall helps us identify the misclassified positive predictions. We use the below formula to calculate recall:
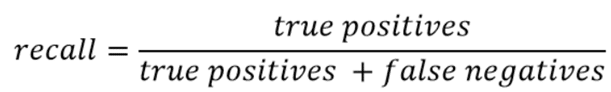
55. What do you understand by a random forest model?
It combines multiple models together to get the final output or, to be more precise, it combines multiple decision trees together to get the final output. So, decision trees are the building blocks of the random forest model.
56. What is RMSE?
RMSE stands for the root mean square error. It is a measure of accuracy in regression. RMSE allows us to calculate the magnitude of error produced by a regression model. The way RMSE is calculated is as follows:
First, we calculate the errors in the predictions made by the regression model. For this, we calculate the differences between the actual and the predicted values. Then, we square the errors.
After this step, we calculate the mean of the squared errors, and finally, we take the square root of the mean of these squared errors. This number is the RMSE, and a model with a lower value of RMSE is considered to produce lower errors, i.e., the model will be more accurate.
57. Explain collaborative filtering in recommender systems.
Collaborative filtering is a technique used to build recommender systems. In this technique, to generate recommendations, we make use of data about the likes and dislikes of users similar to other users. This similarity is estimated based on several varying factors, such as age, gender, locality, etc.
If User A, similar to User B, watched and liked a movie, then that movie will be recommended to User B, and similarly, if User B watched and liked a movie, then that would be recommended to User A.
In other words, the content of the movie does not matter much. When recommending it to a user what matters is if other users similar to that particular user liked the content of the movie or not.
58. Explain boosting in Data Science.
Boosting is one of the ensemble learning methods. Unlike bagging, it is not a technique used to parallelly train our models. In boosting, we create multiple models and sequentially train them by combining weak models iteratively in a way that training a new model depends on the models trained before it.
In doing so, we take the patterns learned by a previous model and test them on a dataset when training the new model. In each iteration, we give more importance to observations in the dataset that are incorrectly handled or predicted by previous models. Boosting is useful in reducing bias in models as well.
59. Mention the different kernel functions that can be used in SVM.
In SVM, there are four types of kernel functions:
- Linear kernel
- Polynomial kernel
- Radial basis kernel
- Sigmoid kernel
60. What is the difference between an error and a residual error?
An error occurs in values while the prediction gives us the difference between the observed values and the true values of a dataset. Whereas, the residual error is the difference between the observed values and the predicted values. The reason we use the residual error to evaluate the performance of an algorithm is that the true values are never known. Hence, we use the observed values to measure the error using residuals. It helps us get an accurate estimate of the error.
61. What do you understand by Survivorship Bias?
This bias refers to the logical error while focusing on aspects that survived some process and overlooking those that did not work due to lack of prominence. This bias can lead to deriving wrong conclusions.
62. Explain bagging in Data Science.
Bagging is an ensemble learning method. It stands for bootstrap aggregating. In this technique, we generate some data using the bootstrap method, in which we use an already existing dataset and generate multiple samples of the N size. This bootstrapped data is then used to train multiple models in parallel, which makes the bagging model more robust than a simple model.
Once all the models are trained, when it’s time to make a prediction, we make predictions using all the trained models and then average the result in the case of regression, and for classification, we choose the result, generated by models, that have the highest frequency.
64. Explain TF/IDF vectorization.
The expression ‘TF/IDF’ stands for Term Frequency–Inverse Document Frequency. It is a numerical measure that allows us to determine how important a word is to a document in a collection of documents called a corpus. TF/IDF is used often in text mining and information retrieval.
65. What are auto-encoders?
Auto-encoders are learning networks. They transform inputs into outputs with minimum possible errors. So, basically, this means that the output that we want should be almost equal to or as close as to input as follows. Multiple layers are added between the input and the output layer and the layers that are in between the input and the output layer are smaller than the input layer. It received unlabelled input. This input is encoded to reconstruct the input later.
66. What is ensemble learning?
When we are building models using Data Science and Machine Learning, our goal is to get a model that can understand the underlying trends in the training data and can make predictions or classifications with a high level of accuracy.
67. How will you balance/correct imbalanced data?
There are different techniques to correct/balance imbalanced data. It can be done by increasing the sample numbers for minority classes. The number of samples can be decreased for those classes with extremely high data points. Following are some approaches followed to balance data:
- Use the right evaluation metrics: In cases of imbalanced data, it is very important to use the right evaluation metrics that provide valuable information.
- Specificity/Precision: Indicates the number of selected instances that are relevant.
- Sensitivity: Indicates the number of relevant instances that are selected.
- F1 score: It represents the harmonic mean of precision and sensitivity.
- MCC (Matthews correlation coefficient): It represents the correlation coefficient between observed and predicted binary classifications.
- AUC (Area Under the Curve): This represents a relation between the true positive rates and false-positive rates.
68. What are the differences between correlation and covariance?
Although these two terms are used for establishing a relationship and dependency between any two random variables, the following are the differences between them:
- Correlation: This technique is used to measure and estimate the quantitative relationship between two variables and is measured in terms of how strong are the variables related.
- Covariance: It represents the extent to which the variables change together in a cycle. This explains the systematic relationship between pair of variables where changes in one affect changes in another variable.
69. Which is faster, python list or Numpy arrays, and why?
A. NumPy arrays are faster than Python lists for numerical operations. NumPy is a library for working with arrays in Python, and it provides a number of functions for performing operations on arrays efficiently.
One reason why NumPy arrays are faster than Python lists is that NumPy arrays are implemented in C, while Python lists are implemented in Python. This means that operations on NumPy arrays are implemented in a compiled language, which makes them faster than operations on Python lists, which are implemented in an interpreted language.
70. Is it good to do dimensionality reduction before fitting a Support Vector Model?
If the features number is greater than observations then doing dimensionality reduction improves the SVM (Support Vector Model). However, sometimes some datasets are very complex, and it is difficult for one model to be able to grasp the underlying trends in these datasets. In such situations, we combine several individual models together to improve performance. This is what is called ensemble learning.
71. How will you validate a multiple regression model?
Adjusted R Squaremetrics helps in validating a multiple regression model. R square tells about how the fitness of data around the regression line. Whenever you add an extra independent variable it will always increase the R-squared value. Therefore, a model with multiple independent variable may seem to fit better even if it isn’t and this where R2 won’t be of help and this is where adjusted R square comes into picture. The value of adjusted R square increases only if the additional variable has higher correlation with the dependent variable and improves the accuracy of the model.
72. What happens if two users access the same HDFS file at the same time?
Ans. This is a bit of a tricky question. The answer itself is not complicated, but it is easy to confuse by the similarity of programs’ reactions.
When the first user is accessing the file, the second user’s inputs will be rejected because HDFS NameNode supports exclusive write.
73. What is the importance of statistics in data science?
Ans. Statistics help data scientists to get a better idea of a customer’s expectations. Using statistical methods, data Scientists can acquire knowledge about consumer interest, behavior, engagement, retention, etc. It also helps to build robust data models to validate certain inferences and predictions.
74. Explain the purpose of group functions in SQL. Cite certain examples of group functions.
Ans. Group functions provide summary statistics of a data set. Some examples of group functions are –
a) COUNT
b) MAX
c) MIN
d) AVG
e) SUM
f) DISTINCT
75. Suppose you are given survey data, and it has some missing data, how would you deal with missing values from that survey?
Ans. This is among the important data science interview questions. There are two main techniques for dealing with missing values –
Debugging Techniques – It is a Data Cleaning process consisting of evaluating the quality of the information collected, increasing its quality, in order to avoid lax analysis. The most popular debugging techniques are –
Searching the list of values: It is about searching the data matrix for values that are outside the response range. These values can be considered as missing, or the correct value can be estimated from other variables
Filtering questions: It is about comparing the number of responses of a filter category and another filtered category. If any anomaly is observed that cannot be solved, it will be considered as a lost value.
Checking for Logical Consistencies: The answers that may be considered contradictory to each other are checked.
Counting the Level of representativeness: A count is made of the number of responses obtained in each variable. If the number of unanswered questions is very high, it is possible to assume equality between the answers and the non-answers or to make an imputation of the non-answer.
- Imputation Technique
This technique consists of replacing the missing values with valid values or answers by estimating them. There are three types of imputation:
- Random imputation
- Hot Deck imputation
- Imputation of the mean of subclasses
CRACK YOUR CAREER WITH DATA SCIENCE COURSE !
76. What is the difference between a bar graph and a histogram?
Ans. Bar charts and histograms can be used to compare the sizes of the different groups. A bar chart is made up of bars plotted on a chart. A histogram is a graph that represents a frequency distribution; the heights of the bars represent observed frequencies.
In other words, a histogram is a graphical display of data using bars of different heights. Generally, there is no space between adjacent bars.
Bar Charts
- The columns are placed on a label that represents a categorical variable.
- The height of the column indicates the size of the group defined by the categories
Histogram
- The columns are placed on a label that represents a quantitative variable.
- The column label can be a single value or a range of values.
77. What is the binomial distribution?
Ans. A binomial distribution is a discrete probability distribution that describes the number of successes when conducting independent experiments on a random variable.
Formula –
Where:
n = Number of experiments
x = Number of successes
p = Probability of success
q = Probability of failure (1-p)
78. Name some of the prominent resampling methods in data science.
Ans. The Bootstrap, Permutation Tests, Cross-validation, and Jackknife.
79. What is power analysis?
Ans. Power analysis allows the determination of the sample size required to detect an effect of a given size with a given degree of confidence.
80. Give one example where both false positives and false negatives are important equally?
In Banking fields: Lending loans are the main sources of income to the banks. But if the repayment rate isn’t good, then there is a risk of huge losses instead of any profits. So giving out loans to customers is a gamble as banks can’t risk losing good customers but at the same time, they can’t afford to acquire bad customers. This case is a classic example of equal importance in false positive and false negative scenarios.
81. Define fsck.
It is an abbreviation for “file system check.” This command can be used for searching for possible errors in the file.
82. Find the distribution of the sum of two random numbers.You have two independent, identical, uniformly distributed random variables x and y ranging between 0 and 1. What distribution does the sum of these two random numbers follow? What is the probability that their product is less than 0.5?
Random variable created by the addition of 2 random variables is again a normal random variable.A quick way to check if the probability of the product of X(0,1) and Y(0,1) is less than 0.5 is to visualize a 2-dimensional plane. All the points (x,y) within the square [0, 1] x [0, 1] fall in the candidate space.The case when xy = 0.5 makes a curve y = 0.5/x, the area under the curve would represent the cases for which xy <= 0.5. Since the area for the square is 1, that area is the sought probability.The curve intersects the square at [0.5,1 ] and [1, 0.5].
83. What is the difference between Type I Error & Type II Error? Also, Explain the Power of the test?
When we perform hypothesis testing we consider two types of Error, Type I error and Type II error, sometimes we reject the null hypothesis when we should not or choose not to reject the null hypothesis when we should.
A Type I Error is committed when we reject the null hypothesis when the null hypothesis is actually true. On the other hand, a Type II error is made when we do not reject the null hypothesis and the null hypothesis is actually false.
The probability of a Type I error is denoted by α and the probability of Type II error is denoted by β.
84. Mention some drawbacks of the Linear Model
Ans. Here a few drawbacks of the linear model:
- The assumption regarding the linearity of the errors
- It is not usable for binary outcomes or count outcome
- It can’t solve certain overfitting problems
- It also assumes that there is no multicollinearity in the data.
85. How is Memory Managed in Python?
Ans. Memory management in Python involves a private heap containing all Python objects and data structures. The management of this private heap is ensured internally by the Python memory manager.
86. Explain Eigenvectors and Eigenvalues
Ans. Eigenvectors depict the direction in which a linear transformation moves and acts by compressing, flipping, or stretching. They are used to understand linear transformations and are generally calculated for a correlation or covariance matrix.
The eigenvalue is the strength of the transformation in the direction of the eigenvector.
An eigenvector’s direction remains unchanged when a linear transformation is applied to it.
87. Mention the types of biases that occur during sampling?
Ans. The three types of biases that occur during sampling are:
a. Self-Selection Bias
b. Under coverage bias
c. Survivorship Bias
88. What Native Data Structures Can You Name in Python? Of These, Which Are Mutable, and Which Are Immutable?
The native python data structures are:
- Lists
- Tuples
- Sets
- Dictionary
Tuples are immutable. Others are mutable.
89. How is k-NN different from k-means clustering?
K-nearest neighbours is a classification algorithm, which is a subset of supervised learning. K-means is a clustering algorithm, which is a subset of unsupervised learning.
And K-NN is a Classification or Regression Machine Learning Algorithm while K-means is a Clustering Machine Learning Algorithm.
K-NN is the number of nearest neighbours used to classify or (predict in case of continuous variable/regression) a test sample, whereas K-means is the number of clusters the algorithm is trying to learn from the data.
90. What is cross-validation?
Cross-validation is a statistical technique that one can use to improve a model’s performance. This is helpful when the model is dealing with unknown data.
91. What are the different types of clustering algorithms?
Ans. Kmeans Clustering, KNN (K nearest neighbour), Hierarchial clustering, Fuzzy Clustering are some of the common examples of clustering algorithms.
92. What is the difference between “long” and “wide” format data?
Ans. Wide-format is where we have a single row for every data point with multiple columns to hold the values of various attributes. The long format is where for each data point we have as many rows as the number of attributes and each row contains the value of a particular attribute for a given data point.
93. What are the support vectors in SVM?
Ans. Support vectors are data points that are closer to the hyperplane and influence the position and orientation of the hyperplane. Using these support vectors, we maximise the margin of the classifier. Deleting the support vectors will change the position of the hyperplane. These are the points that help us build our SVM.
94. How would you effectively represent data with 5 dimensions?
Ans. It can be represented in a NumPy array of dimensions (n*n*n*n*5)
95. What are Autoencoders?
Ans. An autoencoder is a kind of artificial neural network. It is used to learn efficient data codings in an unsupervised manner. It is utilised for learning a representation (encoding) for a set of data, mostly for dimensionality reduction, by training the network to ignore signal “noise”. Autoencoder also tries to generate a representation as close as possible to its original input from the reduced encoding.
96. How can outlier values be treated?
Ans. Outlier treatment can be done by replacing the values with mean, mode, or a cap off value. The other method is to remove all rows with outliers if they make up a small proportion of the data. A data transformation can also be done on the outliers.
97. Explain the SVM machine learning algorithm in detail.
Ans. SVM is an ML algorithm which is used for classification and regression. For classification, it finds out a muti dimensional hyperplane to distinguish between classes. SVM uses kernels which are namely linear, polynomial, and rbf. There are few parameters which need to be passed to SVM in order to specify the points to consider while the calculation of the hyperplane.
Ans. NumPy and SciPy are python libraries with support for arrays and mathematical functions. They are very handy tools for data science.
99. What is __init__ in Python?
Ans. “__init__” is a reserved method in python classes. It is known as a constructor in object-oriented concepts. This method is called when an object is created from the class and it allows the class to initialise the attributes of the class.
100. Why Is Re-sampling Done?
Ans. Resampling is done to:
- Estimate the accuracy of sample statistics with the subsets of accessible data at hand
- Substitute data point labels while performing significance tests
- Validate models by using random subsets
As the industry grows, companies are looking for more data scientists. This can raise the level of the interview. As a result, Entri App attempts to prepare you for the advanced level. If you have any questions about any of the answers, please leave a comment and we will gladly assist you.








{kind=link}