

Table of Contents
Have you ever wondered how email providers implement spam filters? Or how online news channels categorize news text? Or how companies do audience sentiment analysis on social media? are you going to, All of this can be done using a machine learning algorithm called Naive Bayes Classifier.
Naive Bayes Classifier Algorithm
- Naive Bayes algorithm is a supervised learning algorithm, which is based on Bayes theorem and used for solving classification problems.
- It is mainly used in text classification that includes a high-dimensional training dataset.
- Naïve Bayes Classifier is one of the simple and most effective Classification algorithms which helps in building the fast machine learning models that can make quick predictions.
- It is a probabilistic classifier, which means it predicts on the basis of the probability of an object.
- Some popular examples of Naive Bayes Algorithm are spam filtration, Sentimental analysis, and classifying articles.
Why is it called Naive Bayes?
The Naive Bayes algorithm is comprised of two words Naive and Bayes, Which can be described as:
- Naive: It is called Naïve because it assumes that the occurrence of a certain feature is independent of the occurrence of other features. Such as if the fruit is identified on the bases of color, shape, and taste, then red, spherical, and sweet fruit is recognized as an apple. Hence each feature individually contributes to identify that it is an apple without depending on each other.
- Bayes: It is called Bayes because it depends on the principle of Bayes’ Theorem.
Join Our Data Science and Machine Learning Course! Enroll Here
Bayes’ Theorem:
1: Which of the following algorithms is most suitable for classification tasks?
- Bayes’ theorem is also known as Bayes’ Rule or Bayes’ law, which is used to determine the probability of a hypothesis with prior knowledge. It depends on the conditional probability.
- The formula for Bayes’ theorem is given as:
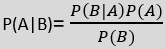
Where,
P(A|B) is Posterior probability: Probability of hypothesis A on the observed event B.
P(B|A) is Likelihood probability: Probability of the evidence given that the probability of a hypothesis is true.
P(A) is Prior Probability: Probability of hypothesis before observing the evidence.
P(B) is Marginal Probability: Probability of Evidence.
🚀 Start Coding Today! Enroll Now with Easy EMI Options. 💳✨
Equip yourself with in-demand skills to land top-tier roles in the data-driven world.
Start Learning Now with EMI OptionsThe Naive Bayes Classifier
The Naive Bayes classifier is an easy-to-use and effective technique for classifying data. It is advised to use the Naive Bayes strategy even if we are working with a data set that has millions of records with certain qualities. When we employ the Naive Bayes classifier for textual data analysis, we get excellent results. Natural language processing, for instance.The Naive Bayes classifier operates according to the Bayes theorem’s definition of conditional probability.
Rev. Thomas Bayes is honored in the Bayes Theorem. On conditional probability, it operates. The likelihood that something will happen provided that something else has already happened is known as the conditional probability. We can determine the likelihood of an event using the conditional probability and our prior knowledge of it.
Example: Consider a fruit to be a watermelon, for instance, if it is green, rounded, and has a 10-inch diameter. Although these characteristics may be interdependent, they all independently increase the likelihood that the fruit under examination is a watermelon. This classifier’s name includes the word “Naive” for that reason.
Types of Naive Bayes Classifiers
Bernoulli Naive Bayes
- Predictors are Boolean variables
- Used when data is as per multivariate Bernoulli distribution
- Popular for discrete features
Multinomial Naive Bayes
- Uses frequency of present words as features
- Commonly used for document classification problems
- Popular for discrete features as well
Gaussian Naive Bayes
- Used when data is as per the Gaussian distribution
- Predictors are continuous variables
Advantages of Naive Bayes
- Easy to work with when using binary or categorical input values.
- Require a small number of training data for estimating the parameters necessary for classification.
- Handles both continuous and discrete data.
- Fast and reliable for making real-time predictions.
Limitations of Naive Bayes
- Assumes that all the features are independent, which is highly unlikely in practical scenarios.
- Unsuitable for numerical data.
- The number of features must be equal to the number of attributes in the data for the algorithm to make correct predictions.
- ‘Zero frequency” problem: If a categorical variable in the test data set has a category that was not included in the training data set, the model assigns it a probability of 0 and cannot make a prediction. This problem can be solved with smoothing procedures, but they are not the subject of this article.
- Computationally expensive when used to classify a large number of items.
Understanding Naive Bayes and Machine Learning
Machine learning falls into two categories:
- Supervised learning
- Unsupervised learning
Supervised learning falls into two categories:
- Classification
- Regression
Naive Bayes algorithm falls under classification.
Join Our Data Science and Machine Learning Course! Enroll Here
Where is Naive Bayes Used?
You can use Naive Bayes for the following things:
Face Recognition
As a classifier, it is used to identify faces or other features such as nose, mouth, eyes, etc.
Weather Prediction
You can use it to predict whether the weather will be good or bad.
Medical Diagnosis
Doctors can diagnose patients by using the information that the classifier provides. Healthcare professionals can use Naive Bayes to indicate if a patient is at high risk for certain diseases and conditions, such as heart disease, cancer, and other ailments.
News Classification
With the help of a Naive Bayes classifier, Google News recognizes whether the news is political, world news, and so on.
As the Naive Bayes Classifier has so many applications, it’s worth learning more about how it works.
How to Implement Naive Bayes Algorithm
The user data set can be used to put the Naive Bayes algorithm into practice in Python. The actions to implement are as follows:
Data preprocessing stage: In this step, you can get the data ready so that your code can use it effectively.
Fitting the Training Set with Naive Bayes: After preprocessing the data, you must fit the Naive Bayes model to the training set. The GaussianNB classifier is used in this step. However, you can also utilize other pertinent classifiers based on your case.
Fitting the Training Set with Naive Bayes: After preprocessing the data, you must fit the Naive Bayes model to the training set. The GaussianNB classifier is used in this step. However, you can also utilize other pertinent classifiers based on your case.
Confusion Matrix Creation: This phase entails evaluating the accuracy of the outcome. To evaluate the accuracy of the Naive Bayes classifier, you must construct the Confusion matrix.
Visualizing the outcome of the training set: Visualizing the results of the Naive Bayes classifier is the next step. If you use the GaussianNB classifier in the code, the result will display a Gaussian curve with isolated data points and fine borders.
Free Tutorials To Learn
| SQL Tutorial for Beginners PDF – Learn SQL Basics | |
| HTML Exercises to Practice | HTML Tutorial | |
| DSA Practice Series | DSA Tutorials | |
| Java Programming Notes PDF 2023 |









{kind=link}