

Table of Contents
Artificial Neural Network (ANN) is a deep learning algorithm that emerged and evolved from the idea of Biological Neural Networks of human brains. An attempt to simulate the workings of the human brain culminated in the emergence of ANN. ANN works very similar to the biological neural networks but doesn’t exactly resemble its workings.

ANN algorithm would accept only numeric and structured data as input. To accept unstructured and non-numeric data formats such as Image, Text, and Speech, Convolutional Neural Networks (CNN), and Recursive Neural Networks (RNN) are used respectively. In this post, we concentrate only on Artificial Neural Networks.
Ace your coding skills with Entri !
Biological neurons vs Artificial neurons
Structure of Biological neurons and their functions
- Dendrites receive incoming signals.
- Soma (cell body) is responsible for processing the input and carries biochemical information.
- Axon is tubular in structure responsible for the transmission of signals.
- Synapse is present at the end of the axon and is responsible for connecting other neurons.
Structure of Artificial neurons and their functions
1: Which of the following algorithms is most suitable for classification tasks?
- A neural network with a single layer is called a perceptron. A multi-layer perceptron is called Artificial Neural Networks.
- A Neural network can possess any number of layers. Each layer can have one or more neurons or units. Each of the neurons is interconnected with each and every other neuron. Each layer could have different activation functions as well.
- ANN consists of two phases Forward propagation and Backpropagation. The forward propagation involves multiplying weights, adding bias, and applying activation function to the inputs and propagating it forward.
- The backpropagation step is the most important step which usually involves finding optimal parameters for the model by propagating in the backward direction of the Neural network layers. The backpropagation requires optimization function to find the optimal weights for the model.
- ANN can be applied to both Regression and Classification tasks by changing the activation functions of the output layers accordingly. (Sigmoid activation function for binary classification, Softmax activation function for multi-class classification and Linear activation function for Regression).
Grab the opportunity to learn Python with Entri! Click Here
🚀 Start Coding Today! Enroll Now with Easy EMI Options. 💳✨
Equip yourself with in-demand skills to land top-tier roles in the data-driven world.
Start Learning Now with EMI OptionsWhy Neural Networks?
- Traditional Machine Learning algorithms tend to perform at the same level when the data size increases but ANN outperforms traditional Machine Learning algorithms when the data size is huge as shown in the graph below.
- Feature Learning. The ANN tries to learn hierarchically in an incremental manner layer by layer. Due to this reason, it is not necessary to perform feature engineering explicitly.
- Neural Networks can handle unstructured data like images, text, and speech. When the data contains unstructured data the neural network algorithms such as CNN (Convolutional Neural Networks) and RNN (Recurrent Neural Networks) are used.
Ace your coding skills with Entri !
How ANN works
The working of ANN can be broken down into two phases,
- Forward Propagation
- Back Propagation
Forward Propagation
- Forward propagation involves multiplying feature values with weights, adding bias, and then applying an activation function to each neuron in the neural network.
- Multiplying feature values with weights and adding bias to each neuron is basically applying Linear Regression. If we apply Sigmoid function to it then each neuron is basically performing a Logistic Regression.

Ace your coding skills with Entri !
🚀 Start Coding Today! Enroll Now with Easy EMI Options. 💳✨
Equip yourself with in-demand skills to land top-tier roles in the data-driven world.
Start Learning Now with EMI OptionsActivation functions
- The purpose of an activation function is to introduce non-linearity to the data. Introducing non-linearity helps to identify the underlying patterns which are complex. It is also used to scale the value to a particular interval. For example, the sigmoid activation function scales the value between 0 and 1.
Logistic or Sigmoid function
- Logistic/ Sigmoid function scales the values between 0 and 1.
- It is used in the output layer for Binary classification.
- It may cause a vanishing gradient problem during backpropagation and slows the training time.
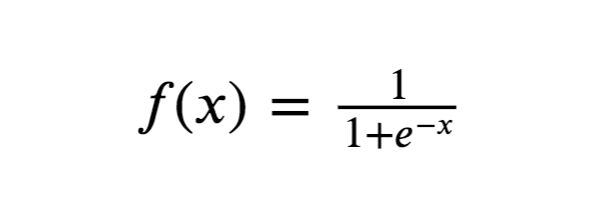
Ace your coding skills with Entri !
Tanh function
- Tanh is the short form for Hyperbolic Tangent. Tanh function scales the values between -1 and 1.
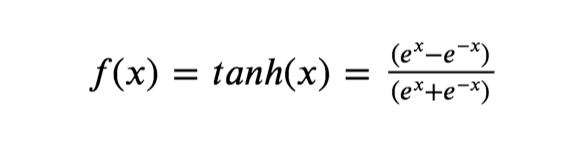
ReLU function
- ReLU (Rectified Linear Unit) outputs the same number if x>0 and outputs 0 if x<0.
- It prevents the vanishing gradient problem but introduces an exploding gradient problem during backpropagation. The exploding gradient problem can be prevented by capping gradients.
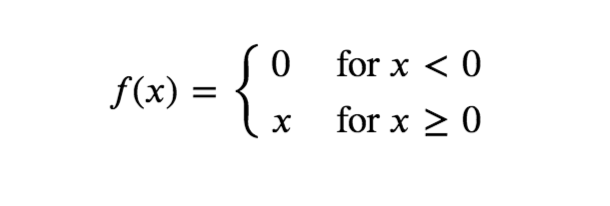
Ace your coding skills with Entri !
Leaky ReLU function
- Leaky ReLU is very much similar to ReLU but when x<0 it returns (0.01 * x) instead of 0.
- If the data is normalized using Z-Score it may contain negative values and ReLU would fail to consider it but leaky ReLU overcomes this problem.
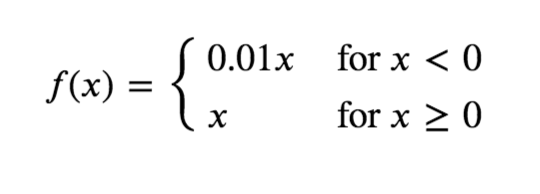
Backpropagation
- Backpropagation is done to find the optimal value for parameters for the model by iteratively updating parameters by partially differentiating gradients of the loss function with respect to the parameters.
- An optimization function is applied to perform backpropagation. The objective of an optimization function is to find the optimal value for parameters.
The optimization functions available are,
- Gradient Descent
- Adam optimizer
- Gradient Descent with momentum
- RMS Prop (Root Mean Square Prop)
The Chain rule of Calculus plays an important role in backpropagation. The formula below denotes partial differentiation of Loss (L) with respect to Weights/ parameters (w).
A small change in weights ‘w’ influences the change in the value ‘z’ (∂𝑧/∂𝑤). A small change in the value ‘z’ influences the change in the activation ‘a’ (∂a/∂z). A small change in the activation ‘a’ influences the change in the Loss function ‘L’ (∂L/∂a).
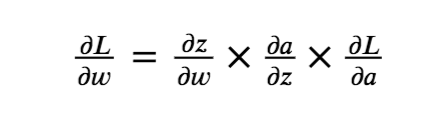
Ace your coding skills with Entri !
Terminologies:
Metrics
- A metric is used to gauge the performance of the model.
- Metric functions are similar to cost functions, except that the results from evaluating a metric are not used when training the model. Note that you may use any cost function as a metric.
- We have used Mean Squared Logarithmic Error as a metric and cost function.
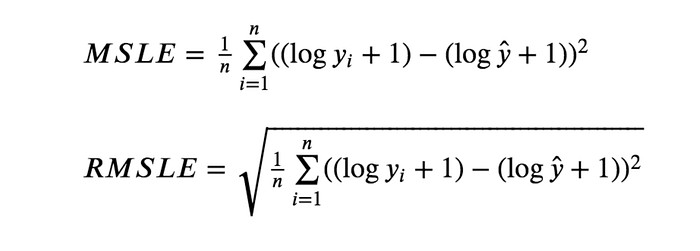
Epoch
- A single pass through the training data is called an epoch. The training data is fed to the model in mini-batches and when all the mini-batches of the training data are fed to the model that constitutes an epoch.
Ace your coding skills with Entri !
Hyperparameters
Hyperparameters are the tunable parameters that are not produced by a model which means the users must provide a value for these parameters. The values of hyperparameters that we provide affect the training process so hyperparameter optimization comes to the rescue.
The Hyperparameters used in this ANN model are,
- Number of layers
- Number of units/ neurons in a layer
- Activation function
- Initialization of weights
- Loss function
- Metric
- Optimizer
- Number of epochs
Grab the opportunity to learn Python with Entri! Click Here
Coding ANN in Tensorflow
Load the preprocessed data
The data you feed to the ANN must be preprocessed thoroughly to yield reliable results. The training data has been preprocessed already. The preprocessing steps involved are,
- MICE Imputation
- Log transformation
- Square root transformation
- Ordinal Encoding
- Target Encoding
- Z-Score Normalization
Ace your coding skills with Entri !
Neural Architecture
- The ANN model that we are going to use, consists of seven layers including one input layer, one output layer, and five hidden layers.
- The first layer (input layer) consists of 128 units/ neurons with the ReLU activation function.
- The second, third, and fourth layers consist of 256 hidden units/ neurons with the ReLU activation function.
- The fifth and sixth layer consists of 384 hidden units with ReLU activation function.
- The last layer (output layer) consists of one single neuron which outputs an array with the shape (1, N) where N is the number of features.
Grab the opportunity to learn Python with Entri! Click Here
Understanding Neural Network
Neural networks are trained and taught just like a child’s developing brain is trained. They cannot be programmed directly for a particular task. Instead, they are trained in such a manner so that they can adapt according to the changing input.
There are three methods or learning paradigms to teach a neural network.
- Supervised Learning
- Reinforcement Learning
- Unsupervised Learning
Ace your coding skills with Entri !
1. Supervised Learning
As the name suggests, supervised learning means in the presence of a supervisor or a teacher. It means a set of a labeled data sets is already present with the desired output, i.e. the optimum action to be performed by the neural network, which is already present for some data sets. The machine is then given new data sets to analyze the training data sets and to produce the correct output.
It is a closed feedback system, but the environment is not in the loop.
2. Reinforcement Learning
In this, learning of input-output mapping is done by continuous interaction with the environment to minimise the scalar index of performance. In this method, a critic converts the primary reinforcement signal, i.e. the scalar input received from the environment, into a heuristic reinforcement signal (higher quality reinforcement signal) scalar input.
This learning aims to minimize the cost to go function, i.e. the expected cumulative cost of actions taken over a sequence of steps.
Ace your coding skills with Entri !
3. Unsupervised Learning
As the name suggests, there is no teacher or supervisor available. In this, the data is neither labeled nor classified, and no prior guidance is available to the neural network. In this, the machine has to group the provided data sets according to the similarities, differences, and patterns without any training provided beforehand.
Working with Neural Network
The neural network is a weighted graph where nodes are the neurons, and edges with weights represent the connections. It takes input from the outside world and is denoted by x(n).
Each input is multiplied by its respective weights, and then they are added. A bias is added if the weighted sum equates to zero, where bias has input as 1 with weight b. Then this weighted sum is passed to the activation function. The activation function limits the amplitude of the output of the neuron. There are various activation functions like the Threshold function, Piecewise linear function, or Sigmoid function.
Ace your coding skills with Entri !
Architecture of Neural Network
There are basically three types of architecture of the neural network.
- Single Layer feedforward network
- Multi-Layer feedforward network
- Recurrent network
1. Single- Layer Feedforward Network
In this, we have an input layer of source nodes projected on an output layer of neurons. This network is a feedforward or acyclic network. It is termed a single layer because it only refers to the computation neurons of the output layer. No computation is performed on the input layer; hence it is not counted.
2. Multi-Layer Feedforward Network
In this, there are one or more hidden layers except for the input and output layers. The nodes of this layer are called hidden neurons or hidden units. The role of the hidden layer is to intervene between the output and the external input. The input layer nodes supply the input signal to the second layer’s nodes, i.e. the hidden layer, and the output of the hidden layer acts as an input for the next layer, which continues for the rest of the network.
3. Recurrent Networks
A recurrent is almost similar to a feedforward network. The major difference is that it at least has one feedback loop. There might be zero or more hidden layers, but at least one feedback loop will be there.
Ace your coding skills with Entri !
Advantages of Neural Network
Given below are the advantages mentioned:
- Can work with incomplete information once trained.
- Have the ability of fault tolerance.
- Have a distributed memory
- Can make machine learning.
- Parallel processing.
- Stores information on an entire network.
- Can learn non-linear and complex relationships.
- Ability to generaize, i.e. can infer unseen relationships after learning from some prior relationships.
Grab the opportunity to learn Python with Entri! Click Here
Required Neural Network Skills
Given below are the required neural network skills:
- Knowledge of applied maths and algorithms.
- Probability and statistics.
- Distributed computing.
- Fundamental programming skills.
- Data modeling and evaluation.
- Software engineering and system design.
Ace your coding skills with Entri !
Why should we use Neural Networks?
- It helps to model the nonlinear and complex relationships of the real world.
- They are used in pattern recognition because they can generalize.
- They have many applications like text summarization, signature identification, handwriting recognition, and many more.
- It can model data with high volatility.
Grab the opportunity to learn Python with Entri! Click Here
Neural Networks Scope
It has a wide scope in the future. Researchers are constantly working on new technologies based on neural networks. Everything is converting into automation; hence they are very much efficient in dealing with changes and can adapt accordingly. Due to an increase in new technologies, there are many job openings for engineers and neural network experts. Hence in the future also neural networks will prove to be a major job provider.
Ace your coding skills with Entri !
How this Technology will help you in Career Growth
There is huge career growth in the field of neural networks. The average salary of a neural network engineer ranges from $33,856 to $153,240 per year approximately.
Grab the opportunity to learn Python with Entri! Click Here
Conclusion – What is Neural Networks?
There is a lot to gain from neural networks. They can learn and adapt according to the changing environment. Moreover, they contribute to other areas as well as in the field of neurology and psychology. Hence there is a huge scope of neural networks in today’s time as well as in the future.









{kind=link}