

Table of Contents
A machine learning model can quickly become overfitted or under fitted during training. To prevent this, we properly fit a model onto our test set using regularisation in machine learning. Regularization methods aid in obtaining the best model by lowering the likelihood of overfitting.

What Are Overfitting and Underfitting?
1: Which of the following algorithms is most suitable for classification tasks?
We provide some data for our machine learning model to learn from. Data fitting is the act of plotting a set of data points and constructing the best fit line to reveal the relationship between the variables. The best fit for our model is when it can identify all relevant patterns in our data while avoiding noise, random data points, and pointless patterns. If we give our machine learning model too much time to examine the data, it will discover numerous patterns in it, including ones that are superfluous. On the test dataset, it will learn extremely quickly and adapt very effectively. It will pick up on significant patterns and noise in our data, but it won’t be able to predict other datasets because of this.
Click here to join machine learning course in Entri app
Overfitting is a situation where the machine learning model attempts to learn from the specifics as well as the noise in the data and tries to fit each data point on the curve. The model is fit for every point in our data. If given new data, the model curves may not correspond to the patterns in the new data, and the model cannot predict it very well in it. On the other hand, the model won’t be able to recognize patterns in our test dataset if it hasn’t had enough opportunities to examine our data. It won’t perform well on new data and won’t fit our test dataset correctly. Underfitting describes a situation in which a machine learning model is unable to predict or categorize a new data point, nor can it understand the link between variables in the testing data. A poorly fitting model can be seen in the diagram below. We can see that it has not properly matched the provided data. It has ignored a sizable portion of the dataset and failed to identify any patterns in the data. It can’t operate on both known and unknown
🚀 Start Coding Today! Enroll Now with Easy EMI Options. 💳✨
Equip yourself with in-demand skills to land top-tier roles in the data-driven world.
Start Learning Now with EMI OptionsWhat are Bias and Variance?
A bias develops when an algorithm’s capacity to learn from data is constrained. Such models oversimplify the model and pay very little attention to the training data; as a result, the patterns in the validation error, prediction error, and training error are identical. These models invariably produce large errors on training and test data. In our model, high bias results in underfitting. The algorithm’s sensitivity to particular kinds of data is determined by variation. The validation error and prediction error are far apart in a model with a high variance because it concentrates on training data and does not generalize. On training data, these models typically exhibit excellent performance, but on test data, they exhibit high error rates. In our model, high variance leads to overfitting.
An ideal model is one that can generalize to new data while still being sensitive to the pattern in our model. When both Bias and Variance are at their best, this occurs. By using regression, we can achieve this bias-variance tradeoff in overfitted or underfitted models. As we can see, when bias is large, both the testing set’s and the training set’s error are also high. The model performs well on our training set and yields a low error when Variance is high, but the error on our testing set is rather high. There is a region in the middle of this where the bias and variance are perfectly balanced to one another, but training and testing errors are minimal.
Click here to join machine learning course in Entri app
What is Regularization in Machine Learning?
Regularization refers to techniques that are used to calibrate machine learning models in order to minimize the adjusted loss function and prevent overfitting or underfitting. Using Regularization, we can fit our machine learning model appropriately on a given test set and hence reduce the errors in it.
Regularization Techniques
There are two main types of regularization techniques: Ridge Regularization and Lasso Regularization.
🚀 Start Coding Today! Enroll Now with Easy EMI Options. 💳✨
Equip yourself with in-demand skills to land top-tier roles in the data-driven world.
Start Learning Now with EMI OptionsRidge Regularization :
It is also referred to as Ridge Regression and modifies over or under-fitted models by applying a penalty equal to the sum of the squares of the coefficient magnitude. As a result, coefficients are produced and the mathematical function that represents our machine learning model is minimised. The coefficients’ magnitudes are squared and summed. Ridge Regression applies regularisation by reducing the number of coefficients. The cost function of ridge regression is shown in the function below: The penalty term is represented by Lambda in the cost function. We can control the punishment term by varying the values of the penalty function. The magnitude of the coefficients decreases as the penalty increases. The settings are trimmed. As a result, it serves to prevent multicollinearity and, through coefficient shrinkage, lower the model’s complexity.
Click here to join machine learning course in Entri app
Take a look at the graph below, which shows linear regression:
Cost function = Loss + λ x∑‖w‖^2
For Linear Regression line, let’s consider two points that are on the line,
Loss = 0 (considering the two points on the line)
λ= 1
w = 1.4
Then, Cost function = 0 + 1 x 1.42
= 1.96
For Ridge Regression, let’s assume,
Loss = 0.32 + 0.22 = 0.13
λ = 1
w = 0.7
Then, Cost function = 0.13 + 1 x 0.72
= 0.62
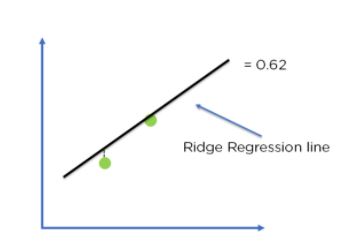
Figure 9: Ridge regression model
Comparing the two models, with all data points, we can see that the Ridge regression line fits the model more accurately than the linear regression line.
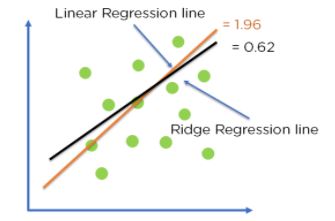
Figure 10: Optimization of model fit using Ridge Regression
Click here to join machine learning course in Entri app
Lasso Regression
By imposing a penalty equal to the total of the absolute values of the coefficients, it alters the models that are either overfitted or underfitted. Lasso regression likewise attempts coefficient minimization, but it uses the actual coefficient values rather than squaring the magnitudes of the coefficients. As a result of the presence of negative coefficients, the coefficient sum can also be 0. Think about the Lasso regression cost function: We can control the coefficient values by controlling the penalty terms, just like we did in Ridge Regression. Again consider a Linear Regression model :
Cost function = Loss + λ x ∑‖w‖
For the Linear Regression line, let’s assume,
Loss = 0 (considering the two points on the line)
λ = 1
w = 1.4
Then, Cost function = 0 + 1 x 1.4
= 1.4
For Ridge Regression, let’s assume,
Loss = 0.32 + 0.12 = 0.1
λ = 1
w = 0.7
Then, Cost function = 0.1 + 1 x 0.7
= 0.8

Comparing the two models, with all data points, we can see that the Lasso regression line fits the model more accurately than the linear regression line.
Regularization Using Python in Machine Learning
Let’s look at how regularization can be implemented in Python. We have taken the Boston Housing Dataset on which we will be using Linear Regression to predict housing prices in Boston. We start by importing all the necessary modules.
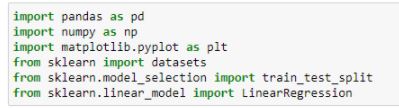
Figure 11: Importing modules in python
We then load the Boston Housing Dataset from sklearn’s datasets.

Figure 12: Loading Boston Housing Dataset
We then convert the dataset into a DataFrame and set the columns and the target variable.
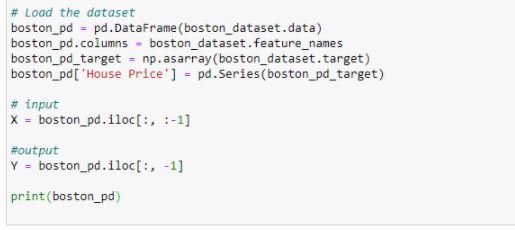
Figure 13: Converting dataset into DataFrame
The below figure shows us the Boston housing dataset.

Figure 14: Boston Housing Dataset
We then split our data into training and testing sets.

Figure 15: Splitting into training and testing sets
We can now use these to train our Linear Regression model. We start by creating our model and fitting the data to it. We then predict on the test set and find the error in our prediction using mean_squared_error. Finally, we print the coefficients of our Linear Regression model.

Figure 16: Linear Regression
The coefficients of our Linear Regression model are given below.
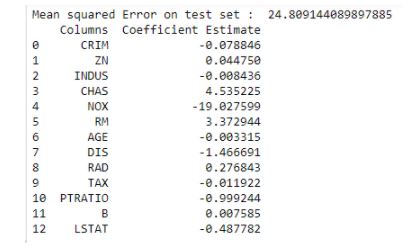
Figure 17: Coefficients of Linear Regression
Now, let’s plot the coefficient score.
Figure 17: Plotting coefficient score of Linear Regression model
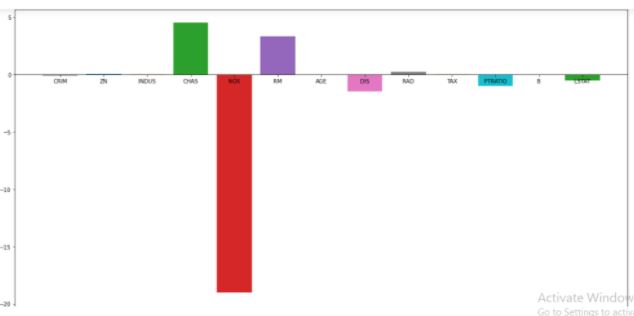
Figure 18: Coefficient score of Linear Regression model
Now, let us perform Ridge regression and plot the new coefficients that we get from it.
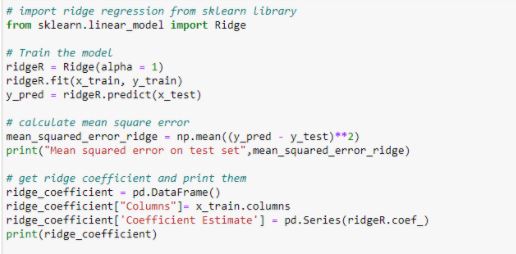
Figure 19: Ridge Regression and plotting coefficients
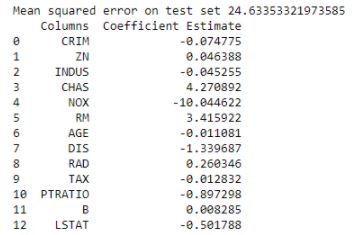
Figure 20: Coefficients of Ridge Regression model
Now let’s plot the coefficient score of the Ridge Regression model

Figure 21: Plotting coefficient score of Ridge Regression model
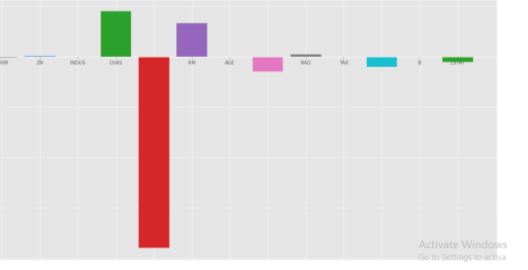
Figure 22: Coefficient score of Ridge Regression model
Let’s perform Lasso Regression and find the coefficients for it.
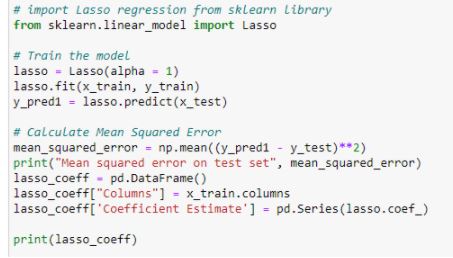
Figure 23: Lasso Regression and plotting coefficients
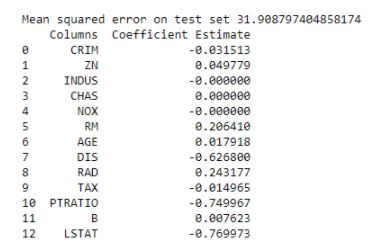
Figure 23: Coefficients of the Lasso Regression model
Conclusion
The different ways that models might become unstable by being under or over-fitted were introduced to us in this article, The Best Guide to Regularization in Machine Learning. Additionally, we observed how bias and variance function in model optimization. After that, we looked at several regularisation strategies to combat over and under-fitting. Finally, a demo showed us how to apply regularisation in Python. Was this regularisation article helpful to you? Do you have any lingering concerns or queries for us? If you leave them in the comments section of this post, we’ll immediately have our experts respond to them.
Free Tutorials To Learn
| SQL Tutorial for Beginners PDF – Learn SQL Basics | |
| HTML Exercises to Practice | HTML Tutorial | |
| DSA Practice Series | DSA Tutorials | |
| Java Programming Notes PDF 2023 |








{kind=link}